
How AI Combines Crop, Soil, and Weather Data to Guide Decisions on Smallholder and Medium Farms — Omdena Case Study
Explore how AI combines crop, soil, and weather data to improve farm decisions in this precision agriculture case study.
May 6, 2026
12 minutes read

Executive Summary
Smallholder and medium-farm decisions rarely fail because the data do not exist. They fail because the data lives in separate systems: weather forecasts here, satellite imagery there, soil maps somewhere else, with the work of integrating it all falling on the farmer or the agronomist who already has a full day of work before picking up their phone. This project built CropLogic, a SaaS precision-agriculture platform that answers one question: how to fuse what is already free and publicly available into reliable, real-time guidance over a 2G or 3G connection.
CropLogic fuses four free, API-ready data streams: Sentinel-2 satellite imagery, ERA5 and GFS weather, OpenET evapotranspiration, and SoilGrids soil maps. It delivers field-level guidance on crop status, irrigation timing, planting windows, and stress alerts without requiring any on-farm hardware and without any license cost to the farmer. It is delivered through an agent-based runtime with explicit fallbacks for missing data and connectivity gaps.
System outputs and reliability
| Output | Primary Signals | Delivery |
|---|---|---|
| Crop stress alert | NDVI/NDRE decline, ET deficit, VPD spike | JSON + mobile summary |
| Irrigation recommendation | AWC, ET deficit, 7-day rainfall, NDVI trend | Probability score + reasoning chain |
| Planting window flag | GDD accumulation, NDVI green-up, precipitation | Advisory with confidence level |
| Harvest timing | NDVI peak, senescence detection, GDD threshold | Alert with the top 2 contributing features |
Why Smallholder and Medium Farm Decisions Break Down
Agriculture has become increasingly data-rich, yet smallholder and medium-farm decisions still operate under a structural disadvantage driven by three compounding gaps. Fragmentation spreads data across separate platforms with incompatible formats and refresh rates, so a simple irrigation question requires manual integration across multiple systems. Connectivity limits mean 2G and 3G networks cannot carry the heavy satellite rasters and IoT feeds that ost ag-tech tools require. Single-source approaches each fail predictably: weather-only systems miss soil conditions, satellite-only systems lose accuracy under cloud cover, and sensor-only systems require expensive per-field deployment.
The result is that field-level intelligence remains out of reach for most operations. Not because the technology does not exist, but because nothing has been designed for the connectivity, hardware, and integration realities these farmers actually live with.
Existing approaches close part of the gap but leave the underlying problem intact. Regional advisory apps, manual agronomist workflows, and single-source satellite dashboards each address one dimension while ignoring the others. A platform that works only on high-bandwidth connections excludes the majority of the target audience due to its architecture. Closing the gap requires integration, connectivity awareness, and resilience under real-world failure modes built in from the start.
Designing from the Constraints Up
This project was designed from the constraints up rather than for ideal conditions first. Every signal pulls from public sources: Sentinel-2, ERA5, GFS, OpenET, SoilGrids, and CropHarvest: no license fees, no data lock-in. Accessibility is a structural property of the platform, not a marketing claim. Heavy raster processing occurs server-side, so phones receive only compact summaries: a vegetation chart, an irrigation cue, or a planting window flag—bandwidth-aware by design, not by workaround.
Multi-source fusion was treated as redundancy rather than a feature. When clouds block Sentinel-2, the system falls back to weather and soil signals. When a sensor reading is faulty, satellite trends and weather provide backup. Fusion ensures no single-source failure breaks the platform. When the system issues a recommendation, it also surfaces the reasoning chain: soil moisture low, ET rising, NDVI declining. Farmers trust integrated signals more than single-index alerts because the chain shows the reasoning behind the recommendation.
Public data only, server-side processing, fusion as redundancy, and surfaced reasoning: none of these are features layered on top of a generic system. They are the structural decisions that determine whether the platform is deployable at all for the operations it is built to serve.
Building the Data Fusion Layer
The data fusion layer integrates four live, API-ready streams. Each source plays a specific role and carries a specific tradeoff that the system was designed to handle.
Four Sources, Four Tradeoffs
1. Sentinel-2
provides 10-metre optical imagery with a roughly 5-day revisit cycle. It drives crop vigor assessments, canopy stress detection, and phenology tracking using NDVI, EVI, NDRE, and NDWI indices, as well as phenological markers such as green-up date, NDVI peak, and senescence timing. The tradeoff is cloud contamination, which creates optical gaps during rainy seasons. For cloud-prone regions, Sentinel-1 SAR backscatter (VV/VH bands) serves as a complement, extending monitoring into periods where optical imagery is unavailable and providing an independent soil moisture proxy.
2. ERA5-Land and NOAA GFS
provide hourly weather reanalysis and forecast data. These drive reference evapotranspiration calculations via FAO-56, Growing Degree Days for crop phenology, and short-term precipitation forecasts. The tradeoff is spatial coarseness: ERA5 at 9 kilometres and GFS at 25 kilometres, both broader than individual field boundaries. Field-level precision comes from fusing weather, satellite, and soil signals, not from weather alone.
3. OpenET
delivers daily field-scale evapotranspiration estimates for the US by combining models such as SSEBop, METRIC, PT-JPL, and geeSEBAL. It is already operational and widely adopted by water managers and agricultural services across the US, with validation studies against flux-tower measurements showing ensemble ET products perform well across most cropland types. Outside the US, the system falls back to FAO-56-based crop ET computation from weather inputs: a known limitation that the system surfaces explicitly when it applies.
4. SoilGrids 2.0
provides static, 250-metre global soil maps for organic carbon, pH, and texture. These feed available water capacity calculations that drive water-balance logic. The maps are static and field-coarse, which the architecture acknowledges as a known limitation that in-field sensors will resolve in later phases. For cloud-prone regions, the planned addition of Sentinel-1 SAR data addresses a documented gap: research consistently shows that fusing optical and radar imagery yields more robust crop monitoring, particularly during rainy seasons when optical coverage fails.
Why was aligning them the real engineering challenge?
Aligning these four sources into a single field-level water balance required significantly more engineering than the modelling layer that used it. Different formats, refresh rates, geographic coverage, and units. Most of the project’s technical complexity lives in this alignment layer, not in the models. Fusion is the load-bearing infrastructure.
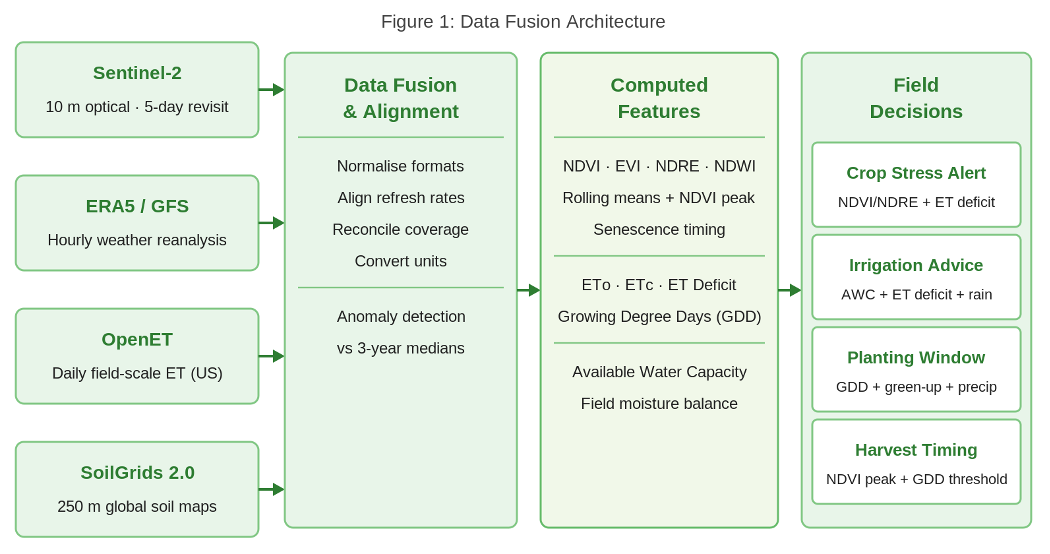
Figure 1: Data fusion architecture: four sources through alignment into computed features and field decisions
What the Pipeline Computes
From satellite data, the pipeline computes vegetation indices (NDVI, EVI, NDRE, NDWI) and their rolling means, as well as phenological markers tracking green-up date, peak canopy health, and senescence timing. From weather data, it derives the reference crop evapotranspiration, cumulative ET deficit, and Growing Degree Days for use in planting window logic. From soil, it calculates available water capacity to drive the field-level water balance. Anomaly detection then compares each current value against three-year medians for the same calendar day, surfacing field-level deviations that are invisible in raw index values alone. Model pretraining leverages CropHarvest, a harmonised global label dataset drawn from Sentinel-2, Sentinel-1, and Landsat time series, enabling crop classifiers to generalise across agroecologies before fine-tuning on local field data.
Model Choice and Why a Baseline Failure Mattered
The team evaluated TempCNN, Transformer-based time-series models, LightGBM, and XGBoost before settling on LightGBM and XGBoost for the MVP. For a multi-region platform with heterogeneous data quality and real-world data gaps, model robustness mattered more than peak benchmark accuracy. Both handle missing inputs gracefully, train faster on smaller per-region datasets, and produce interpretable feature attributions that feed directly into the farmer-facing reasoning chain. TempCNN and Transformers are reserved for later phases where dense Sentinel-2 time series and accumulated field labels make them the right fit.
Before multi-source fusion was integrated, the team built a baseline classifier to validate whether weather data alone could drive harvest-readiness predictions. The test used ERA5-Land reanalysis data from Hungarian agricultural regions spanning 2015 to 2025, with input features including air temperature, total precipitation, vapour pressure deficit, and four soil water volumetric layers (swvl1 through swvl4). Three models were evaluated on a time-based split: Logistic Regression, Random Forest, and HistGradientBoosting. All three achieved an AUC of approximately 0.5, the random-guess baseline, with perfect recall but zero precision.
AUC of 0.5 is not a model failure. It is a data failure: a controlled, reproducible confirmation that single-source weather inputs provide insufficient phenological signal for harvest-readiness decisions. The baseline was explicitly designed to set up the next validation step: integrating Sentinel-2 NDVI and EVI time series alongside SMAP soil moisture to test whether multi-source fusion recovers the signal that weather alone cannot provide. This result is the empirical foundation on which the entire platform architecture rests.
Decision Logic and the Agent-Based Runtime
Predictions create value only when they translate into actions farmers can confidently take. CropLogic’s decision logic combines rule-based safeguards with ML probability outputs, designed around three principles.
How Predictions Become Decisions
Rules encode conservative safety. Hard constraints prevent dangerous recommendations even when ML output suggests otherwise. If a soil sensor indicates moisture below a defined threshold, the system will not recommend withholding irrigation, regardless of the model’s output. The system also runs active contradiction detection: if satellite imagery shows high NDVI while a soil sensor reads critically dry, the discrepancy is flagged for manual agronomist review rather than automatically resolved from either signal alone.
ML outputs are probability scores, not binary recommendations. A stress probability of 0.62 indicates an elevated stress risk, with the top two contributing factors identified, but not as an immediate action directive. Probabilities are converted into recommendations using thresholds calibrated to asymmetric error costs. A concrete example: irrigate if available soil water is below 40%, the 7-day ET deficit exceeds a defined threshold, and the NDVI trend is declining. Three independent signals must agree before the system issues a recommendation, keeping false alarms low while avoiding missed real stress events.
Uncertainty is made explicit, not hidden. Every recommendation returns a confidence score and the top contributing features. Farmers see the reasoning chain behind the alert. High-cost actions such as full irrigation cycles or fertiliser applications require farmer confirmation before the system commits.
The four-agent architecture
The decision workflow runs through four specialised agents orchestrated by LangGraph with explicit fallbacks, timeouts, and circuit breakers. ContextSummarizerAgent structures the query context. FeatureOrchestratorAgent pulls live data, computes features, and triggers a RAG-based fallback after a 20-second timeout from the data source. CropHealthModelAgent runs ML inference with a circuit breaker that opens after two consecutive failures, then defaults to rule-based recommendations. EnhancedResponseRefinementAgent formats the final output as structured JSON for mobile, SMS, and dashboard delivery.
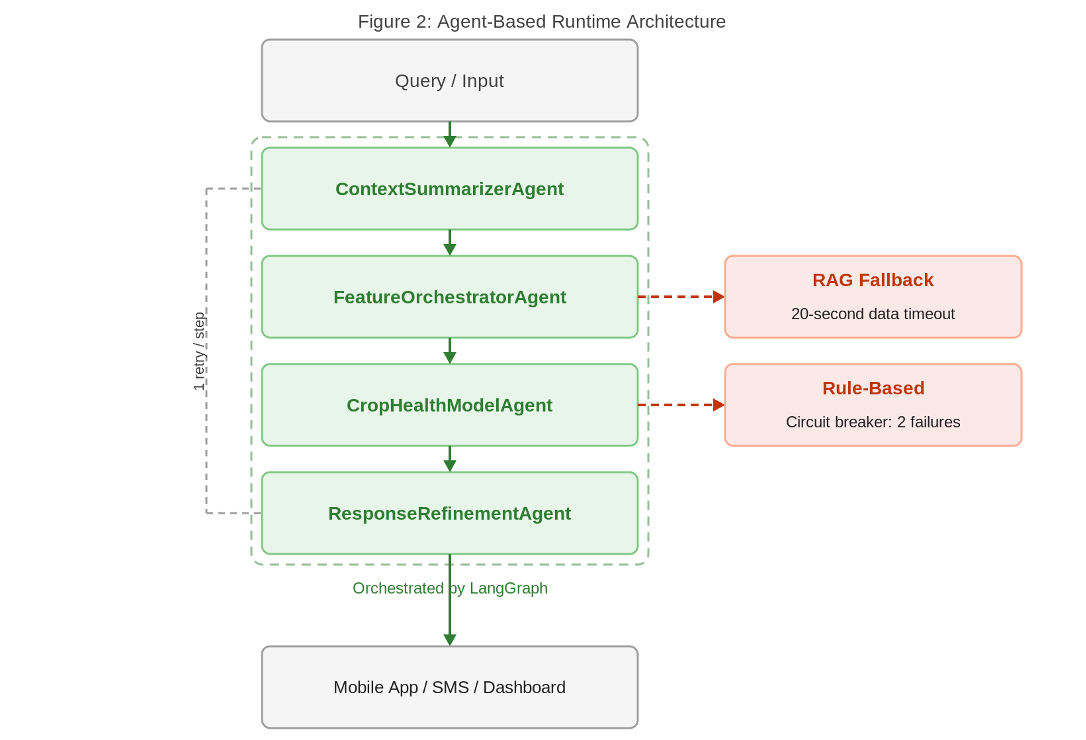
Figure 2: Four-agent runtime with RAG and rule-based fallback paths, orchestrated by LangGraph
Graceful degradation under real-world failure
Agent-based architecture is not a novelty for its own sake. For a system that handles missing data, model failures, and connectivity drops, modular agents with explicit fallbacks are what keep it operational. Each agent retries once before failing over. The logging agent was deferred by design to keep the runtime lean for the MVP. A test suite of 96 tests across CI and local environments validates the flow end-to-end. Monolithic systems fail catastrophically. This one fails gracefully.
Deployment and Real-World Constraints
Deployment was designed from the reality of connectivity outward. All satellite raster ingestion, weather data integration, ET computation, and ML inference happen server-side. What reaches the phone is a vegetation index chart, an irrigation cue, a planting window flag, or a stress alert with explanation, measured in kilobytes rather than megabytes. When connectivity drops, the last successful assessment is cached locally, and the request automatically retries on reconnection.
The system has known limitations, as the architecture explicitly acknowledges. OpenET coverage is US-only, so non-US irrigation recommendations rely on FAO-56 estimates at lower confidence. Sentinel-2 has predictable cloud-contamination gaps during rainy seasons, which will be addressed by integrating Sentinel-1 SARs in future phases. Static SoilGrids maps do not capture within-field soil variation, so operations with high spatial heterogeneity will see lower confidence in recommendations until in-field sensors are added.
In agricultural ML deployments, data coverage and quality are the recurring binding constraints, not algorithmic sophistication. The honey-harvesting baseline confirmed this quantitatively; real deployment seasons confirmed it operationally. CropLogic is designed for this reality: the constraints do not disappear, but the architecture manages them honestly rather than hiding them behind false confidence scores.
What This Project Proves
These are the lessons from CropLogic that transfer beyond this platform. Each reflects a structural truth about AI deployments in data-constrained, infrastructure-limited environments.
- Fragmentation across data systems, not data scarcity, is the binding constraint on smallholder and medium farm decision-making. The data exists. The integration does not. Closing the integration gap is more valuable than adding new data sources.
- Designing for the connectivity and hardware constraints farmers actually live with determines whether a platform is deployable at all. Tools designed for high-bandwidth, high-end phone operations exclude the majority of the target audience due to their architecture.
- Multi-source fusion is not a nice-to-have for accuracy. It is a structural requirement. Single-source systems fail predictably due to cloud failures, sensor faults, or coverage limits. Fusion provides redundancy, and that redundancy is what keeps the platform operational under real-world failure modes.
- Model robustness to missing inputs and graceful degradation matter more than benchmark accuracy. LightGBM and XGBoost handle real-world data failures more reliably than architecturally complex alternatives. Production stability is the metric that actually matters.
- Agent-based runtime architecture turns fragile monolithic ML systems into resilient platforms. When data sources fail, models fail, and connectivity drops, modular agents with explicit fallbacks fail gracefully, whereas monolithic systems fail catastrophically. Agent architecture is how decision-support AI becomes operationally reliable.
About the Project
This case study documents CropLogic, a collaborative AI initiative developed by Omdena. Cross-functional teams of data scientists, agronomists, and engineers worked together on a real-world, applied challenge: building a SaaS precision-agriculture platform that fuses satellite, weather, and soil data for smallholder and medium farms operating on limited connectivity and hardware. The platform emphasises connectivity-aware design, agent-based architecture, and explainable recommendations that farmers can act on with confidence.
The shift this project represents is worth naming clearly: from designing for ideal data conditions and degrading for real ones, to designing from the constraints up. In smallholder and medium farming systems, where 2G connectivity, mid-range smartphones, and free public data are the operating reality, the advantage goes to platforms that treat these constraints as first-class design inputs. CropLogic is a concrete demonstration of that shift.
If you are evaluating AI-powered advisory platforms for a smallholder or medium farm network, or looking to integrate multi-source data fusion into an existing agronomic service, reach out to the Omdena team to discuss how this architecture applies to your context.