
AI for Predicting Missing Soil Nutrients and Improving Fertilizer Decisions – Omdena Case Study
Can AI replace soil lab tests? Omdena's case study shows ML predicting SOC at 80% accuracy to improve fertilizer decisions for smallholder farmers.
May 4, 2026
9 minutes read

Executive Summary
Fertilizer decisions rarely fail due to poor agronomic practices. They fail because of incomplete information. Most soil analyses capture macronutrients (nitrogen, phosphorus, and potassium), whereas critical variables such as soil organic carbon (SOC), boron, and zinc are routinely omitted. These are not secondary measurements. SOC governs soil structure, water retention, and nutrient availability. Boron and zinc directly affect plant metabolism, root development, and yield formation.
This project built a machine learning system to predict these missing soil nutrients using inputs that are already commonly available. The final model delivered consistent, generalizable performance:
| Nutrient | R² Score | Reliability |
|---|---|---|
| Soil Organic Carbon (SOC) | ≈ 0.80 | Strong: suitable for decision support |
| Boron | ≈ 0.68 | Moderate: usable with confidence bounds |
| Zinc | ≈ 0.52 | Limited: not yet reliable for recommendations |
SOC and boron predictions show strong practical potential for fertilizer decision support. Zinc remains more difficult to predict reliably, a finding that points to a data availability gap rather than a model failure. The system was deployed via a FastAPI backend and Streamlit interface, making predictions accessible to agronomists and extension workers in real time.
The Problem: Where Fertilizer Decisions Quietly Break Down
Agriculture has become increasingly data-driven, yet soil management still operates with a fundamental gap. The most important variables are often missing when decisions are made, particularly in smallholder systems where testing resources are limited.
Standard soil testing captures nitrogen, phosphorus, potassium, and pH. This provides a baseline, but it doesn’t explain how soil actually behaves under field conditions. SOC determines how well soil retains water and supports nutrient cycling. Boron and zinc influence plant metabolism and the effectiveness of applied fertilizers in translating into yield.
Consider a field with adequate NPK readings. At first glance, fertilizer application appears sufficient. But if SOC is low, nutrient retention and water availability decline, reducing fertilizer efficiency. Without visibility into SOC, this performance loss is consistently misattributed. The core issue isn’t incorrect practice. It’s decision-making under incomplete soil information.

Soil health decisions are often made by hand and by instinct. AI-driven nutrient prediction adds a data layer to that judgment. Image Source: Pexels.
Why Traditional Methods Don’t Close the Gap
There are established methods for measuring soil nutrients, but they weren’t designed for continuous, large-scale use in smallholder contexts.
Laboratory testing provides accurate results, but cost and turnaround time make frequent sampling impractical for most smallholder farmers. Field sensors have improved accessibility but typically capture only macronutrients. As a result, key micronutrients remain routinely unmeasured.
Fertilizer decisions are constrained by what can be affordably tested, not by what is agronomically needed. Over time, this gap creates inefficiencies that are difficult to detect and costly to sustain.
A Practical Shift: Predict Instead of Measure
This project approached the problem differently. Instead of expanding measurement, it shifted focus to prediction.
Soil systems are interconnected. Nutrient availability, soil texture, and environmental conditions influence each other in measurable ways. When these relationships are modeled effectively, missing nutrients can be estimated with useful accuracy from data that’s already available.
The correlation matrix below illustrates this directly. Strong relationships exist between variables like SOC and nitrogen, boron and geographic location, and zinc and potassium. These are the patterns the model learns to use for prediction.
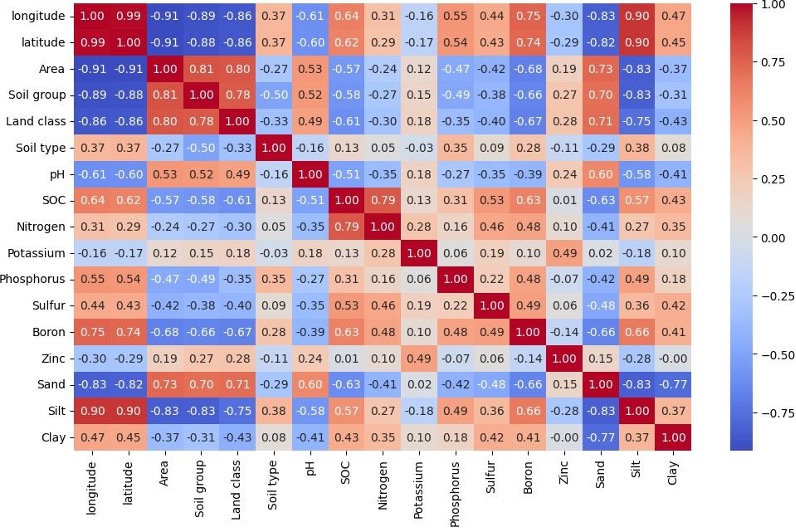
Figure 1: Correlation matrix across all soil variables in the dataset. Strong inter-variable relationships, particularly between SOC and nitrogen, form the basis for predicting missing nutrients from available inputs.
The system predicts SOC, boron, and zinc from commonly available soil and environmental inputs, adding a layer of soil intelligence that complements rather than replaces traditional testing—the key advantage: better fertilizer decisions without requiring additional soil sampling.
Building the System: Where Most of the Work Happened
The dataset combined soil sensor data from Bangladesh with open-source data from the iSDA African Soil Information Service, producing over 2,500 records covering multiple soil attributes.
Using iSDA data (derived primarily from African soils) alongside Bangladesh field data was a deliberate methodological choice. African soils in the iSDA dataset span a much wider range of soil textures, organic carbon concentrations, and micronutrient profiles than the Bangladesh sensor data alone could provide. This diversity helped the model learn generalized soil relationships rather than overfitting to a narrow regional pattern.
The two datasets were not directly compatible. Soil classifications were represented differently, measurement units varied, and key nutrients present in one dataset were absent in the other. The team resolved this through careful preprocessing: soil type categories were converted to sand, silt, and clay percentages using the soil texture triangle; units were standardized; missing values were imputed; and outliers were removed. This stage required considerably more effort than model development itself and proved far more consequential. Once the data was properly aligned, model performance improved substantially. Before that, it did not.
Model Development: Why Simpler Beats More Complex
Several machine learning approaches were evaluated: Random Forest, CatBoost, and automated pipelines. Random Forest and CatBoost achieved R² values above 0.95 on the training data, but results looked promising until they were tested on held-out data, where performance dropped substantially. The models had learned noise from the training set rather than stable soil relationships.
Ridge Regression told a different story. Its training R² reached 0.97 for SOC and 0.95 for boron, comparable to the more complex models, but its test scores held at 0.80 and 0.68, respectively. That narrower gap between training and test performance, maintained consistently across validation runs, made it the clear choice for deployment.
This outcome reflects a pattern that recurs in agricultural data science: when training data is noisy or sourced from heterogeneous environments, model stability matters more than model capacity.
Results: What the Model Delivered
The final model delivered measurable, differentiated performance across the three target nutrients:
- SOC: R² ≈ 0.80. Strong and suitable for integration into fertilizer decision workflows.
- Boron: R² ≈ 0.68. Moderate and usable with appropriate confidence bounds.
- Zinc: R² ≈ 0.52. Limited and not yet reliable enough for consistent recommendations.
Zinc’s lower performance is not a model failure. It reflects an insufficient signal in the available data. Zinc availability in soil is governed by factors such as pH, redox conditions, and cation exchange capacity, which were not fully captured in this dataset. In soil nutrient modeling, performance gaps reliably indicate what data is missing, not what the model got wrong. Results apply to conditions similar to those in the training data and may vary across different regions, soil types, and environmental contexts.
From Prediction to Decisions in the Field
Predicting soil nutrients only creates value when it changes what decisions get made. This system allows fertilizer strategies to move beyond regional averages and reflect actual soil conditions at the field level.
In Bangladesh’s smallholder farming systems, where comprehensive soil testing is financially and logistically out of reach for most farmers, this approach provides a practical route to improved fertilizer efficiency without increasing cost burden. Estimating missing nutrients reduces reliance on frequent laboratory testing, enables more targeted application of inputs, improves efficiency, and reduces waste.
Deployment: From Model to Usable System
The system was designed for real-world use from the outset. A FastAPI backend handles data processing and model inference. A Streamlit interface allows users to input soil parameters, visualize soil patterns, and generate predictions in real time.
The deployed dashboard (shown below) provides geospatial visualization of soil data, interactive feature analysis, and a live data table. Agronomists and extension workers can explore patterns, filter by soil group or land class, and generate predictions without writing a single line of code.
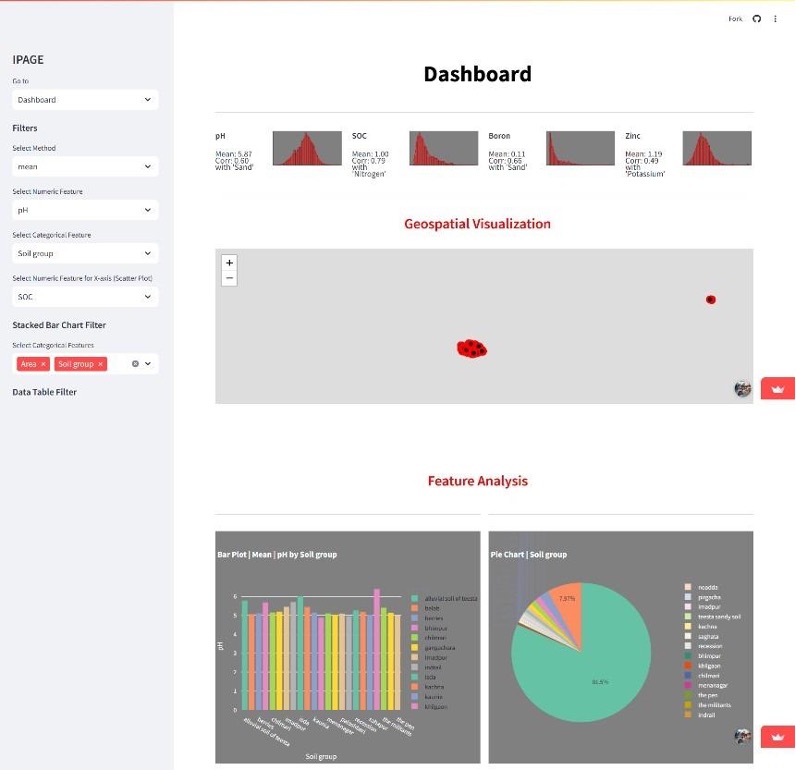
Streamlit dashboard showing geospatial soil visualization, SOC boron and zinc predictions, and interactive feature analysis
The system was built end-to-end with usability in mind. A model that cannot reach the people it was built for does not solve a real problem. This one was designed with that principle at its core.
Challenges: What Actually Limited the System
The primary constraint was data availability. Micronutrient records were sparse, and integrating multiple sources with different formats and measurement conventions added significant complexity to preprocessing. Government dataset approvals introduced delays, requiring the team to rely more heavily on open-source data than originally planned.
More expressive models initially showed strong performance during training but consistently failed to generalize. This reinforces the core finding: in agricultural ML, data quality and coverage are the binding constraints, not algorithmic sophistication.
What Comes Next
The current system is a working first generation, with clear pathways for improvement. Expanding datasets across additional regions, integrating real-time IoT sensor feeds, and incorporating additional soil chemistry variables will improve predictive coverage and reliability.
Zinc prediction stands to benefit most from broader geographic data and variables capturing cation exchange capacity, pH interactions, and organic matter dynamics, the factors most strongly linked to zinc availability in soil. As data coverage grows, the system can evolve from a proof of concept into a comprehensive fertilizer decision-support platform.
Key Takeaways
- Missing micronutrient data (particularly SOC, boron, and zinc) is a primary structural limitation in fertilizer decision-making for smallholder farmers.
- Machine learning can predict soil nutrients from existing inputs with practically useful accuracy: R² of 0.80 for SOC and 0.68 for boron.
- Model stability matters more than complexity when training data is noisy or multi-source. Ridge Regression outperformed more complex alternatives by more than 15 R² points on held-out data.
- Preprocessing and data alignment are often the most consequential stages of agricultural ML, more so than model selection.
- Zinc’s R² of 0.52 signals a data availability gap, not a model failure. It is a useful diagnostic pointing to where future data collection should focus.
About the Project
This case study documents a collaborative AI initiative developed by Omdena, in which cross-functional teams of data scientists, agronomists, and engineers work together on real-world, applied challenges. The project applied machine learning to soil nutrient prediction in Bangladesh, with an emphasis on practical usability, data-driven decision support, and deployment in smallholder farming contexts.
A Shift Worth Naming
The shift this project represents is worth naming clearly: from collecting more data to extracting more value from the data that already exists. In agricultural systems where comprehensive soil measurement will remain out of reach for most smallholders, the advantage goes to those who can make better decisions with what’s available. This project is an early, practical demonstration of how that shift works in practice, and what it can deliver when data quality is taken seriously.