If you’ve spent any time building Retrieval-Augmented Generation (RAG) systems, you’ve likely hit the “Layout Wall.” You build a beautiful pipeline, feed it a complex PDF form or a financial report full of charts, and ask: “What was the revenue growth in Q3?”
The result? A confident hallucination or a vague “I don’t know.”
This is where multimodal document parsing for RAG becomes essential. Traditional pipelines extract text, but production-grade systems must interpret text, layout, and visuals together to preserve meaning.
The problem isn’t your LLM; it’s your parser. Most RAG pipelines treat PDFs as a flat stream of characters, ignoring the fact that in the real world, meaning is distributed across text, layout, and graphics.
In this article, you’ll learn how multimodal parsing helps RAG systems handle forms and visually rich reports, why traditional text extraction fails, and what architectural changes are required to make complex documents reliably retrievable. To understand why this shift matters, we first need to define what multimodal parsing actually means in the context of RAG.
TL;DR (Quick Summary):
Multimodal document parsing for RAG enables systems to understand text, layout, and visuals together instead of treating documents as plain text.
Most RAG failures on PDFs, forms, and reports happen because traditional parsing ignores charts, tables, and spatial structure.
Forms require field-level parsing (label-value pairs), while visual documents require extracting meaning from charts, figures, and layouts.
Tools like Unstructured, LlamaParse, AWS Textract, Donut, and LayoutLMv3 are commonly used, often in hybrid pipelines.
Multimodal chunking preserves relationships between text, visuals, and structure, which improves retrieval accuracy and reduces hallucinations.
Improving multimodal document parsing for RAG often delivers better results than switching to a larger language model.
What is Multimodal Document Parsing for RAG?
Multimodal document parsing for RAG is the process of extracting meaning from documents that contain more than just text. Many real-world documents include structure and visuals such as layouts, charts, tables, and diagrams.
Traditional parsing converts everything into plain text, but that approach often loses important context. Modern RAG systems perform better when they can understand not only what the text says, but also how information is organized and presented visually.
Multimodal parsing moves beyond basic OCR or layout detection by combining textual content, spatial structure, and visual meaning into a unified representation. This allows retrieval systems to interpret documents more accurately and produce grounded answers.
In enterprise environments, meaning is often distributed across these different elements, which makes multimodal understanding essential for reliable RAG performance. This shift directly impacts how accurately RAG systems retrieve and ground information.
Why Multimodal Parsing Improves RAG Accuracy
RAG systems depend on retrieving the right context before generating answers. When documents contain structure or visuals, text-only parsing often misses key signals that influence meaning. Multimodal parsing improves grounding by preserving how information is presented, not just what is written.
This leads to more precise retrieval. Forms remain intact as structured data, while charts and figures are interpreted alongside text rather than ignored.
With better context, the language model no longer has to guess missing details, which directly reduces hallucinations.
In practice, this means answers are supported by real document content instead of inferred patterns.
By improving grounding and retrieval precision at the parsing stage, multimodal pipelines strengthen the reliability of RAG outputs across complex, real-world documents. To understand how this works in practice, it’s useful to look at the end-to-end pipeline behind multimodal document parsing.
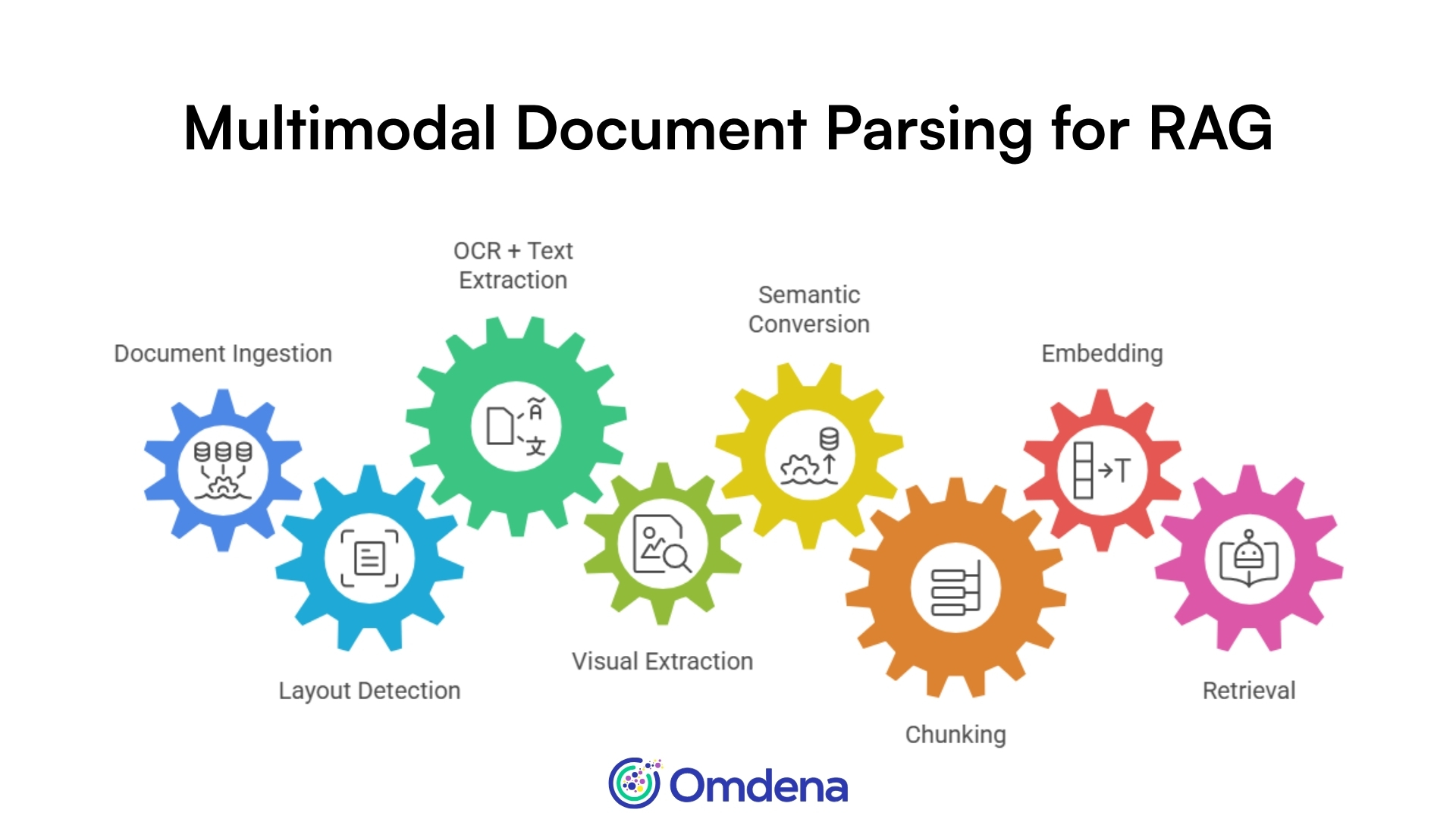
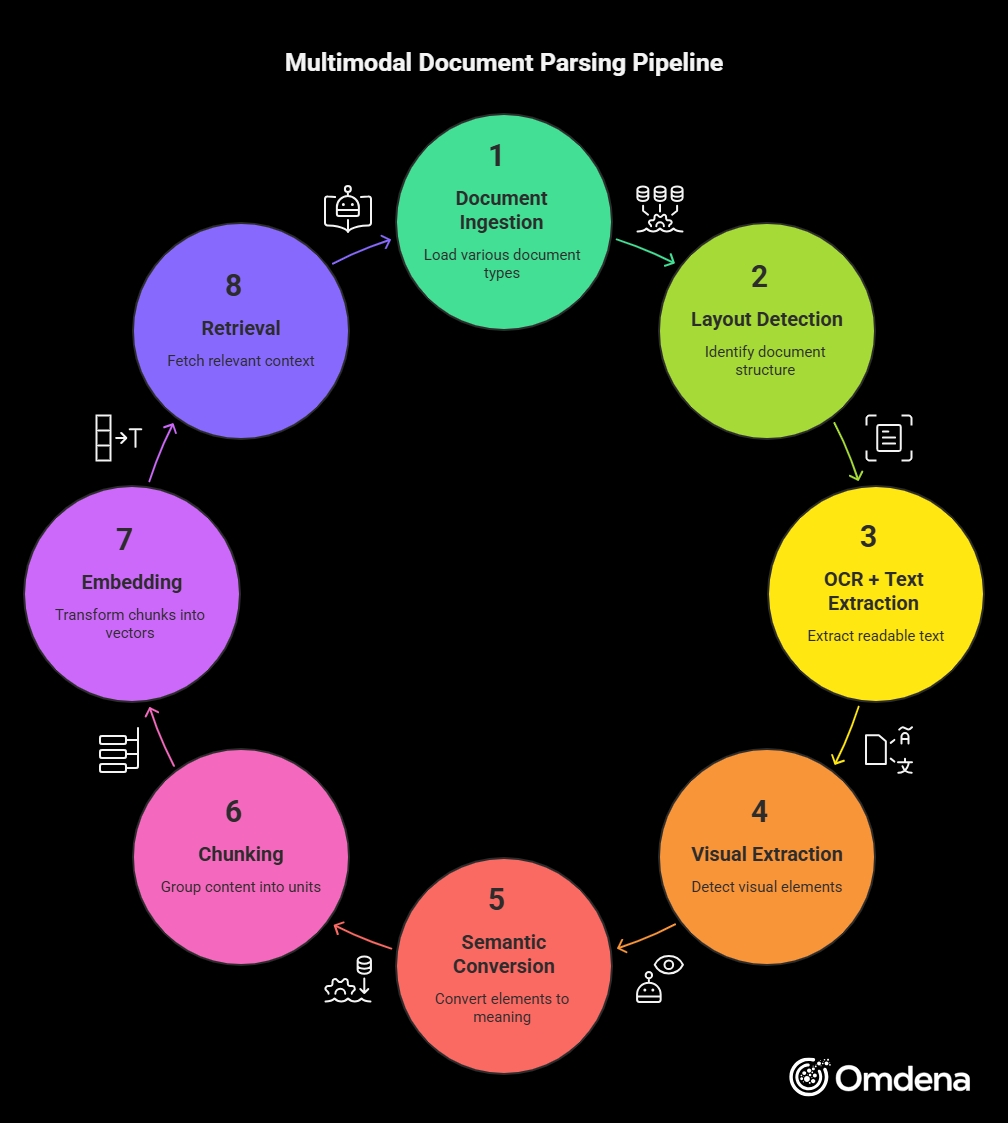
End-to-End Multimodal Document Parsing Pipeline
A reliable multimodal RAG system depends on how well each stage of the parsing pipeline captures both textual and visual meaning.
Multimodal-Document-Parsing-Pipeline
Document ingestion → Load PDFs, images, or structured files from various sources
Layout detection → Identify document structure such as sections, columns, and blocks
OCR + text extraction → Extract readable text from digital or scanned content
Visual extraction → Detect charts, images, and figures within the document
Semantic conversion → Convert visual and textual elements into machine-readable meaning
Chunking → Group content into context-aware units such as sections or figure-caption pairs
Embedding → Transform chunks into vector representations for retrieval
Retrieval → Fetch the most relevant multimodal context for a given query
Each step builds on the previous one, and errors early in the pipeline can impact retrieval quality downstream. The next step is choosing the right tools to implement this pipeline effectively in real-world systems.
Best Tools for Multimodal Document Parsing
Choosing the right tools is essential for building a reliable multimodal parsing pipeline, as different solutions handle text, layout, and visuals with varying levels of accuracy and scale.
Tool
Best For
Strength
Unstructured
General parsing
Structured output across formats
LlamaParse
Complex documents
High accuracy and layout preservation
AWS Textract
OCR-heavy workflows
Scalable extraction for forms and tables
Donut
Vision-based parsing
End-to-end document understanding without OCR
LayoutLMv3
Layout and text understanding
Strong multimodal representation learning
In practice, most production systems combine multiple tools to balance accuracy, cost, and performance across document types.
To choose the right approach, it is important to first understand how different documents represent meaning in RAG systems.
Multimodal Document Types in RAG Systems
Before designing any parsing strategy, the first question to ask is: what kind of document are you working with?
A common mistake in RAG pipelines is treating every PDF the same. In reality, documents differ in how they encode meaning, and multimodal parsing must begin with classification.
Most enterprise documents fall into two main categories:
Forms (Field-Centric Documents): These documents represent meaning through structured elements like label–value pairs, checkboxes, and grouped fields. Examples include medical forms, insurance claims, and compliance records.
Born-Digital Visual-Rich Hybrids: These documents contain readable text but rely on charts, graphs, and diagrams to convey key insights. Examples include financial reports, ESG disclosures, and research papers.
Each type expresses information differently, so parsing logic must adapt to the document class even though the downstream RAG system remains unified.
Multimodal Parsing for Forms in RAG
Forms are not narratives.
They are semantic graphs of:
Forms as Semantic Graphs
If you chunk a form by tokens, you break it. If you miss one label–value pairing, retrieval fails quietly. The goal here is not paragraph understanding. The goal is field accuracy.
We preserve spatial structure from the beginning.
Instead of:
Python
text = extract_text("form.pdf")
We do this:
Python
from pdf2image import convert_from_path
import pytesseract
pages = convert_from_path("form.pdf")
ocr_results = []
for page in pages:
data = pytesseract.image_to_data(page, output_type=pytesseract.Output.DICT)
ocr_results.append(data)
We retain bounding boxes. Because layout matters.
Linking Labels to Values
Most failures happen here.
A simple heuristic approach looks like this:
Python
def link_label_value(lines):
pairs = []
for y, tokens in lines.items():
if ":" in tokens:
idx = tokens.index(":")
label = " ".join(tokens[:idx])
value = " ".join(tokens[idx+1:])
pairs.append((label.strip(), value.strip()))
return pairs
In production, we augment this with:
Layout-aware models
Spatial proximity logic
Semantic similarity checks
Because misaligned fields silently corrupt retrieval.
Schema Alignment, Where LLMs Actually Help
Even if extraction works, normalization becomes messy fast.
LLMs can assist in schema alignment, mapping heterogeneous field labels into a canonical schema dynamically. Instead of hardcoding every variation, the model reasons about semantic equivalence and aligns fields to predefined schema targets.
This turns normalization from a brittle rules problem into a controllable semantic mapping layer.
Once normalized, each field becomes its own retrievable unit:
Python
chunks = [
{
"field_name": normalize_field(label),
"content": value
}
for label, value in pairs
]
This is field-level chunking. Not token chunking. And that difference is structural.
Multimodal Parsing for Visual Documents in RAG
Now let’s move to the harder class.
Financial reports.
Research papers.
ESG documents.
They look like text documents. They are not.
They are narrative + layout + charts.
And charts are often where the actual insight lives.
If your RAG pipeline ignores visuals, your model will hallucinate trends that are clearly visible in a graph.
Extracting Layout-Aware Structure
We begin with block-level extraction:
Python
import fitz # PyMuPDF
doc = fitz.open("report.pdf")
blocks = []
for page in doc:
blocks.extend(page.get_text("blocks"))
Each block contains coordinates, which allow us to reconstruct:
Reading order
Section boundaries
Caption proximity
Without layout metadata, section integrity collapses.
Figures Must Be Explicitly Detected
Most pipelines ignore images.
Python
for page in doc:
images = page.get_images(full=True)
for img in images:
xref = img[0]
pix = fitz.Pixmap(doc, xref)
pix.save(f"image_{xref}.png")
Now we have the visual elements. But pixels aren’t retrievable. Meaning is.
Converting Visual Meaning into Text
Charts often encode trends that don’t appear explicitly in the surrounding text.
So we convert visual semantics into structured descriptions:
Python
prompt = """
Describe the chart and extract:
- Main trend
- Key comparisons
- Anomalies
- Time period
"""
This creates machine-readable summaries.
Now charts become retrievable objects, not blind spots.
Context-Aware Chunking
Instead of fixed token windows, we chunk by semantic unit:
Token-based chunking may seem efficient, but it often breaks the structure that gives documents meaning.
It can:
Split label–value pairs in forms
Separate figures from their captions
Disrupt narrative flow within sections
Increase the chances of retrieving irrelevant context
These issues rarely trigger visible errors. Instead, they gradually degrade retrieval quality and answer grounding. As a result, teams often try to compensate by upgrading models, when the real problem lies in how the document was structured in the first place.
Evaluation: Why “Human-in-the-Loop” is Non-Negotiable
Evaluating parsing quality is non-trivial because no single universal metric exists. We assess success at two levels:
Parsing-Level Metrics: For forms, we measure field-level precision and recall for label-value pairs. For hybrid documents, we assess section integrity and figure-caption association accuracy.
RAG-Aware Evaluation: We measure the impact on the downstream task, specifically, retrieval hit rates and the reduction in hallucinations.
The Importance of Human-in-the-Loop (HITL): Even with the best automated metrics, Human-in-the-Loop validation remains a critical component for production systems. Automated fuzzy matching can fail on subtle errors that humans catch instantly.
HITL serves three vital roles:
Ground Truth Generation: Manually reviewing parsed structures to create high-quality benchmarks for your models.
A/B Testing: Directly comparing RAG answers generated before and after parsing improvements to quantify the “real-world” impact.
Continuous Improvement: Identifying silent field omissions or misalignment that automated scripts might miss.
The Future of Reliable RAG Starts with Multimodal Parsing
Multimodal document parsing for RAG is no longer optional. As enterprise knowledge increasingly lives inside structured forms, layouts, and visual reports, pipelines must move beyond text-only extraction to achieve reliable retrieval and grounded answers.
By treating structure and visuals as first-class information sources, organizations can reduce hallucinations, improve retrieval accuracy, and unlock insights that traditional parsing overlooks.
If you’re looking to build a custom RAG system that can truly understand complex documents, the Omdena team can help. Book an exploration call to discuss your use case and learn how multimodal parsing can strengthen your AI pipeline for real-world deployment.
FAQ
What is multimodal document parsing?
Multimodal document parsing is the process of extracting meaning from documents that contain multiple types of information such as text, layout, and visuals like charts or tables. Instead of converting everything into plain text, it preserves structure and visual context so RAG systems can retrieve more accurate information.
Why does RAG fail on visual documents?
RAG often fails on visual documents because traditional parsing ignores charts, diagrams, and layout relationships. When key insights live inside visuals or structured fields, text-only extraction misses critical context, leading to incomplete retrieval or hallucinated answers.
How does multimodal parsing reduce hallucinations?
By preserving structure and visual meaning, multimodal parsing improves retrieval accuracy. When the correct context is retrieved, the language model has better grounding, which reduces the likelihood of generating unsupported or incorrect responses.
Is multimodal parsing required for enterprise RAG?
In enterprise environments where knowledge exists in forms, reports, and visual dashboards, multimodal parsing is essential. Without it, RAG systems risk missing key information and producing unreliable outputs.
Continue with Omdena
Share this article
Share on LinkedIn, send by email, or copy the direct link.