
How to Webscrape 700,000 PDFs for Natural Language Processing in 14 Hours to Help the Planet
61x times faster! How to webscrape environmental policy documents from government pages combining more than 9MM URLs.

March 6, 2021
7 minutes read

In order to identify financial incentives for forest and landscape restoration in LATAM, we needed to webscrape policy documents from government pages combining more than 1,300 keywords for each of the 108 targetted states. We did this 61x times faster (than using a laptop only) by leveraging Apify and AWS. In the article, you read how we scraped 9MM URLs that gave us 738k unique URLs of PDFs to be downloaded. We unified this in a single CSV file to be further downloaded.
Why we need to build a huge dataset
You might ask why creating a dataset with 700,000 PDFs for Natural Language Processing (NLP) may help the planet?
Here´s the answer.
At Omdena we deal with many different Artificial Intelligence (AI) projects where data scientists from around the world go hands-on with organizations, communities, and technology partners to solve meaningful and impactful problems.
In this context, we started a project with the World Resources Institute (WRI) where 50 AI changemakers applied NLP to identify financial incentives for forest and landscape restoration. The focus was on Latin America (most specifically Mexico, Peru, Chile, Guatemala, and El Salvador).

Deforestation: Photo by Boudewijn Huysmans on Unsplash
Using NLP to mine policy documents, we would be able to promote knowledge sharing between stakeholders and enable rapid identification of incentives, disincentives, perverse incentives, and misalignment between policies.
If a lack of incentives or disincentives were discovered, this would provide an opportunity to advocate for positive change. Creating a systematic analysis tool could enable a standardized approach to generate data that can help craft policies that restore more degraded land more quickly.
The problem
In the beginning, we had a starting dataset of a few dozens of PDFs provided by WRI to allow us to train the NLP models and we established a task team to web scrape many more as these models are heavily dependent on lots of data.
The main sources of policies for the five countries were the websites of the Federal Official Gazettes. We successfully accessed each one and by using Scrapy and Selenium we retrieved tens of thousands of documents. Besides the federal documents we also needed to retrieve policies from the state and regional levels to train the NLP algorithms to work at the scales WRI needed.
However these five countries have 108 states and regions in total and accessing each of the Official Gazettes for each of these would be impractical as we neither had enough time, nor the computational resources and team size needed.
Google?
As search engines usually index the whole spectrum of internet pages we started to think our answer could be in Google as it is the main page indexer available.
But how could we scrape Google in search of 1,300 combined keywords for each of those 108 states and regions in a quick and effective way?
And more than that, assuming that we could have all the Google results that we wanted, how could we download those documents quickly and cost-effectively?
How we did it
To answer those we needed to scrape Google in an almost unlimited way, but the problem is that Google protects its data very effectively by adopting restrictions to IPs that behave like scrappers. One way to bypass that is by using IP rotating proxies: you set different IPs that will rotate for predefined and as much unpredictable possible length of time for each set of keywords to disguise Google efforts to block or ban this IP. So we could build a solution using that but even though our estimates showed us that it would take much more time than we had.
Apify
Then we started to shop around to see where to find a ready tool to do the task fast. We found Apify. Apify is a one-stop-shop for web scraping, data extraction, and RPA needs. They have a huge set of services to scrape Facebook pages, Instagram, Amazon, Airbnb, Twitter, Youtube, Tripadvisor, IMDb, many more… and Google Search Results Scraping! We contacted them and readily established a great partnership.
For Google SERPs in Apify, it is possible to work either via console or programmatically via their API. We chose the console and upload JSON files with the queries needed and setting many parameters like language (Spanish), country code (for each one), number of results per page (with a number bigger than 100 results per query the retrieved URLs became too much unrelated to our query. We chose 100 results per page to be faster as possible), number of concurrent queries (we established the maximum value (100) for it to be as fast as possible), exact geolocation (one for each country), among many other parameters.
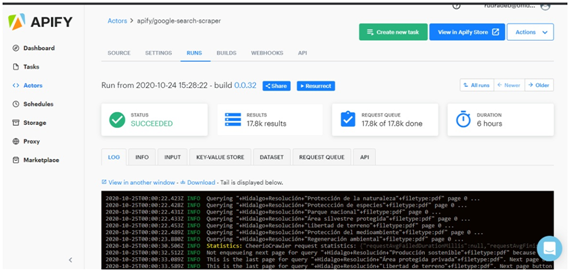
Figure 1 — Apify task running multiple queries
To feed the queries we used a keyword structuring that consisted of [Geo Keywords — for each of the 108 states and regions] + [Type of legal documents keywords] + [Knowledge Domain Keywords — specific to the environmental terms we were looking for] + filetype: pdf (as we just wanted PDFs).
So we had 142k different queries to run in Apify and we divided those into separated JSONs and ran 10 parallel tasks in Apify. The longest execution time was 8 hours for the biggest JSON file. With those, we generated approximately 9MM URLs that gave us 738k unique URLs of PDFs to be downloaded. We unified this in a single CSV file to be further downloaded.
AWS
Then we moved to AWS and built a 100% serverless architecture to help with the downloading problem. We used horizontal scaling to scale five Lambdas allowing each one to send 150k URLs in batches of 10 URLs to SQS for further downloading.
You may be asking why we didn´t download the URLs directly from the start but Lambda has a maximum execution time of 15 minutes. So it would be impossible to have that many parallel Lambdas needed to download this huge amount of documents. A way of bypassing that is to break these tasks into smaller tasks with an execution time of fewer than 15 minutes. So sending those URLs to an SQS queue and using this queue to trigger a Lambda to download 10 URLs each, allows each Lambda to download up to 10 documents in less than 15 minutes making it feasible. We also used approximately 900 concurrent Lambdas to accelerate the total download time.
Because of this architecture, we downloaded the documents in 5,5 hours, creating a dataset of 2,4Tb data in S3. Also because of the availability of the websites in the downloading moment, we managed to download 672k (or 91% of the original documents).
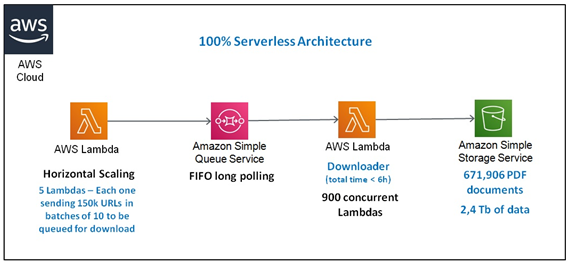
FIGURE 2–100% Serverless Architecture on AWS
The results
I downloaded a sample of 1,000 documents to my local machine and extrapolating the time taken, it would have taken 2 weeks using my machine and internet connection (100 Gbps) uninterruptedly to download them all.
So using AWS Lambda and Amazon SQS we were able to complete it in 5,5 hours or 61x faster than in my local computer!
To scrape Google for the 740k URLs from an EC2 instance would require a huge amount of IP proxies making it very expensive. Besides, there would be a limitation regarding internet connection and probably we would need to use many EC2 instances combined with these IP rotating proxies to download these URLs in a reasonable time what would make the costs more prohibitive. So basically we wouldn´t have the needed resources in time and money to achieve this scale of results and without Apify we couldn´t have done this.
By using both Apify and AWS allowed us to complete this huge task in less than 14 hours!
Our estimates are that we spent around US$ 0,15 per Gb of highly qualified information which makes this method a cost-effective one. Besides, it is also a highly available solution and quickly replicable for our future projects.
I´d like to make a special thanks to Erika Ureña and Jordi Planas who actively participated in making this happen in an indispensable way. Also, I´d like to thank all my colleagues at Omdena who have worked on this challenge.
Last but not least a very special thanks to our great partner Apify, who trusted in our capabilities and without whom this would not have been achieved.
This article is written by Leonardo Sanchez.


